,
I probably won't be doing any new posts til next week unfortunately. In the interim, I thought it might be worth drawing attention to a new paper I have written on the topic of human enhancement and the common good. Just to show that I do try to do write some other stuff outside of the blog.
The paper is entitled "On the Need of Epistemic Enhancement: Democratic Legitimacy and the Enhancement Project" and it is due to be published in the next issue of Law, Innovation and Technology. A pre-publication version can be found here and here.
Monday, February 25, 2013
Thursday, February 21, 2013
Feedback?

Things are likely to be a little light on the blogging front over the next week and half (not that they're ever particularly "heavy"), so I thought now might be an ideal time to solicit some feedback from readers. I'm keeping the questions general for now, so all I'm wondering is:
- What don't you like about the blog?
- What do you like about the blog?
- How could it be improved (from your perspective)?
It might help if I offered my own thoughts about the first two questions. On the first, I think there are several problems with this blog: infrequency and inconsistency in posting, overly didactic and expository posts, largely one-way conversation between writer and readers, no real engagement with other blogs, and numerous broken promises about potential series of posts.
At the same time, I think the material I produce (when I get around to it) is of a reasonably high quality, though the word-count on each post has been going up. And perhaps the didactic and expository nature of the posts contrasts nicely with more typical blogs.
So that's what I've been thinking, what do you think?
Friday, February 15, 2013
AIs and the Decisive Advantage Thesis

One often hears it claimed that future artificial intelligences could have significant, possibly decisive, advantages over us humans. This claim plays an important role in the debate surrounding the technological singularity, so considering the evidence in its favour is worthy enterprise. This post attempts to do just that by examining a recent article by Kaj Sotala entitled “Advantages of Artificial Intelligences, Uploads and Digital Minds”. (Edit: Kaj chimes in with some clarifications and corrections in the comments section. Be sure to check them out)
The post is in two parts. The first part explains exactly how the claim of decisive advantage — or as I shall it “The Decisive Advantage Thesis” (DAT) — affects debates surrounding the technological singularity. The second part is then a more straightforward summary and consideration of the evidence Sotala presents in favour of the DAT (though he doesn’t refer to it as such). The post is somewhat light on critical commentary. It is primarily intended to clarify the arguments supporting the DAT and its connection to other important theses.
1. The Relevance of the DAT
Before looking at the evidence in its favour, it’s worth knowing exactly why the DAT is important. This means tracing out the logical connections between the DAT and other aspects of the debate surrounding the technological singularity. As I have pointed out before, much of that debate is about two core theses. The first of these — the Explosion Thesis — states that it is likely that at some point in the future there will arise a greater-than-human artificial intelligence (AI+) which will create even more intelligent machines, which will in turn create more intelligent machines, in a positive feedback cycle. This is referred to as the intelligence explosion. To put it slightly more formally:
The Explosion Thesis: It is probably that there will be an intelligence explosion. That is: a state of affairs in which for every AIn that is created, AIn will create a more intelligent AIn+1 (where the intelligence gap between AIn+1 and AIn increases) up to some limit of intelligence or resources.
There are several arguments in favour of the Explosion Thesis, some of which are surveyed in Chalmers (2011), but the classic statement of the argument can be found in the writing of I.J. Good. As he put it:
Let an ultraintelligent machine be defined as a machine that can far surpass all the intellectual activities of any man however clever. Since the design of machines is one of these intellectual activities, an ultraintelligent machine could design even better machines; there would then unquestionably be an 'intelligence explosion,' and the intelligence of man would be left far behind. Thus the first ultraintelligent machine is the last invention that man need ever make.
As you can see, embedded within this argument is the DAT. The key motivating premise of Good’s argument is that an ultraintelligent machine will be better than human beings at designing intelligent machines. But that premise itself depends on the assumption that those machines will be better than human beings across all the key cognitive dimensions needed to create intelligent machines. But that is simply to say that those machines will have a decisive advantage over humans across all those dimensions. If the advantages were not decisive, we would already have an intelligence explosion. Hence, the DAT provides significant support for the Explosion Thesis.
The second core thesis in the singularity debate — the Unfriendliness Thesis — holds that prospect of AI+ should be somewhat disquieting. This is because it is likely that any AI+ that is created would have goals and values that are inimical to our own.
The Unfriendliness ThesisSV: It is highly likely (assuming possibility) that any AI+ or AI++ that is created will have values and goals that are antithetical to our own, or will act in a manner that is antithetical to those values and goals.
The connection between the DAT and the Unfriendliness Thesis is not direct, as it was in the case of the Explosion thesis, but it reveals itself if we look at the following, “doomsday” argument:
- (1) If there is an entity that is vastly more powerful than us, and if that entity has goals or values that contradict or undermine our own, then doom (for us) is likely to follow.
- (2) Any AI+ that we create is likely to be vastly more powerful than us.
- (3) Any AI+ that we create is likely to have goals and values that contradict or undermine our own.
- (4) Therefore, if there is AI+, doom (for us) is likely to follow.
The second premise, which is crucial to the overall argument, relies on the claim being made by the DAT. The “unfriendliness” of any potential AI+ is only really disquieting if it has a decisive power advantage over us. If an AI+ had unfriendly goals and values, but (a) didn’t have the means or the ability to achieve those goals; and (b) the means and abilities it did have were no greater than those of other human beings, then there would be nothing too great to worry about (at least, nothing greater than what we already worry about with unfriendly human beings). So, once again, the DAT provides support for a key argument in the singularity debate.
2. Support for the DAT
Granting that the DAT is important to this debate, attention turns to its little matter of its truth. Is there any good reason to think that AI+s will have decisive advantages over human beings? Superficially, yes. We all know that computers are faster and more efficient than us is certain respects, so if they can acquire all the competencies needed in order to secure general intelligence (or, more precisely, “cross-domain optimisation power”) there is something to be said in favour of the DAT. In his article, Sotala identifies three general categories of advantages that AI+s may have over human beings. They are: (a) hardware advantages; (b) self-improvement advantages; and c) cooperative advantages. Let’s look at each category in a little more detail.
A human brain is certainly a marvelous thing, consisting of approximately a hundred-billion neurons all connected together in an inconceivably vast array of networks, communicating through a combination of chemical and electrical signalling. But for all that it faces certain limitations that a digital or artificial intelligence would not. Sotala mentions three possible advantages that an AI+ might have when it comes to hardware:
Superior processing power: Estimates of the amount of processing power required to run an AI range up to 1014 floating point operations per second (FLOPs), compared with up to 1025 FLOPs for a whole brain emulation. In other words, an AI could conceivable do the same work as a human mind with less processing power, or alternatively it could do much more work for the same or less. (At least, I think that’s the point Sotala makes in his article; I have to confess I am not entirely sure what he is trying to say on this particular issue).
Superior Serial Power: “Humans perceive the world on a characteristic timescale” (p. 4), but an artificial intelligence could run on a much faster timescale, performing more operations per second than a human could. Even a small per-second advantage would accumulate over time. Indeed, the potential speed advantages of artificial intelligences have led some researchers to postulate the occurrence of a speed explosion (as distinct from an actual intelligence explosion). (Query: Sotala talks about perception here, but I can’t decide whether that’s significant. Presumably the point is simply that certain cognitive operations are performed faster than humans, irrespective of whether the operations are conscious or sub-conscious. Human brains are known to perform subconscious functions much faster than conscious ones.).
Superior parallel power and increased memory: Many recent advances in computing power have been due to increasing parallelisation of operations, not improvements in serialisation. This would give AIs an advantage on any tasks that can be performed in parallel. But it also creates some problems for the DAT as it may be that not all intelligence-related operations are capable of being parallelised. In addition to this though, AIs would have memory advantages over human beings, both in terms of capacity and fidelity of recall, this could prove advantageous when it comes to some operations.
Humans have a certain capacity for self-improvement. Over the course of our lives we learn new things, acquire new skills, and become better at skills we previously acquired. But our capacity for self-improvement faces certain limitations that artificial intelligences could overcome. This is what Sotala’s second category of advantages is all about. Again, he notes three such advantages:
Improving algorithms: As is well-known, computers use algorithms to perform tasks. The algorithms used can be improved over time. They become faster, consume less memory, and rely on fewer assumptions. Indeed, there is currently evidence (cited by Sotala in the article) to suggest improvements in algorithm efficiency have been responsible for significant improvements on a benchmark production planning model in the recent past.
Creating new mental modules: It is well-known that specialisation leads can be advantageous. Improvements in productivity and increases in economic growth are, famously, attributed to it. Adam Smith’s classic paean to the powers of the market economy, The Wealth of Nations, extolled the benefits of specialisation using the story of the pin factory. The human brain is also believed to achieve some of its impressive results through the use of specialised mental modules. Well, argues Sotala, an AI could create even more specialised modules, and thus could secure certain key advantages over human beings. A classic example might be by creating new sensory modalities, that can access and process information that is currently off-limits to humans.
New motivational systems: Human self-improvement projects often founder on the rocks of our fickle motivational systems. I know this to my cost. I frequently fail to acquire new skills because of distractions, limited attention span, and weakness of the will. AIs need not face such motivational obstacles.
Humans often do amazing things by working together. The CERN project in Geneva, which recently confirmed the existence of the Higgs-Boson, is just one example of this. It was through the combined efforts of politicians, institutions and thousands of scientists and engineers, that this endeavour was made possible. But humans are also limited in their capacity for cooperative projects of this sort. Petty squabbling, self-interest and lack of tact frequently get in the way (though these things have their advantages). AIs could avoid these problems with the help of three things:
Perfect Cooperation: AIs could operate like hiveminds or superorganisms, overcoming the cooperation problems caused by pure self-interest. (Query: I wonder if this really is as straightforward as it sounds. It seems to me like it would depend on the algorithms the AIs adopt, and whether some capacity for self-interest might be a likely “good trick” of any superintelligent machine. Still, the analogy with currently existing superorganisms like ant colonies is an intriguing one, though even there the cooperation is not perfect).
Superior Communication: Human language is vague and ambiguous. This is often a motivator of conflict (just ask any lawyer!). Machines could communicate using much more precise languages, and at greater speed.
Copyability: One thing that leads to greater innovation, productivity and efficiency among humans is the simple fact that there are more and more of them. But creating more intelligent human beings is a time- and resource-consuming operation. Indeed, the time from birth to productivity is increasing in the Western world, with more time spent training and upskilling. Such timespans would be minimised for AIs, who could simply create fully functional copies of their algorithms.
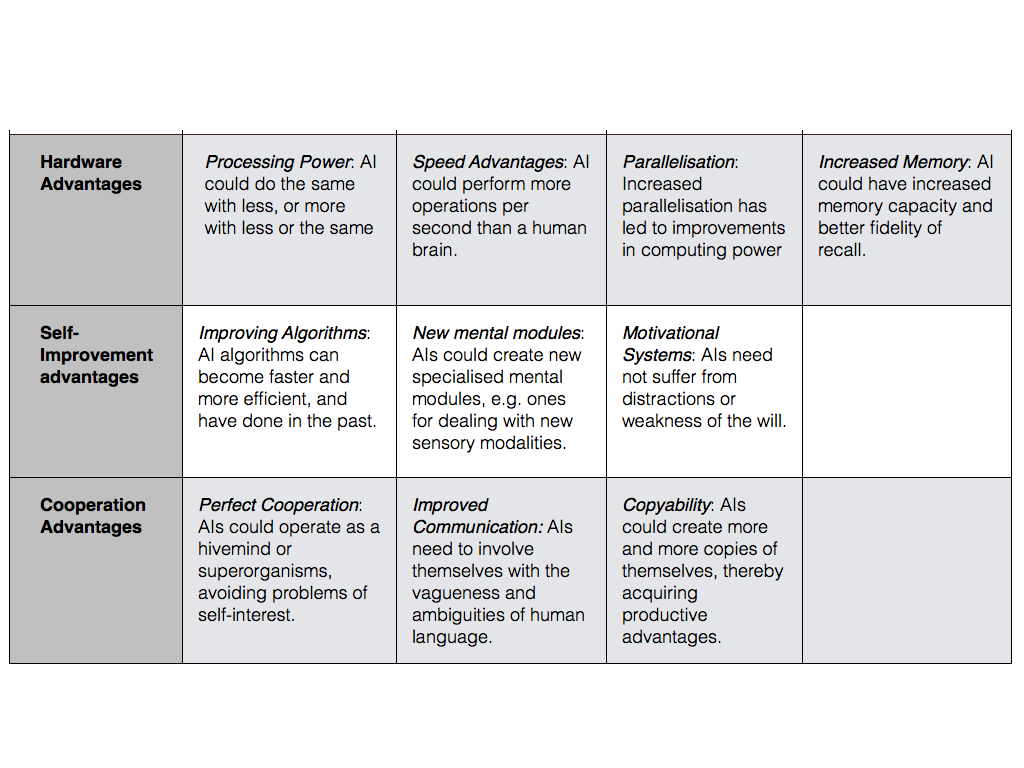
All these advantages are summarised in the table above. In addition to them, there are a variety of advantages related to the avoidance of human biases, but I won't get into those here.
Taken together, these advantages form a reasonably powerful case for the DAT. That said, they are not quite enough in themselves. If we go back to our earlier concern with the singularity debate, we see that the links between these kinds of advantages and the Explosion Thesis or the Doomsday Argument are a little sketchy. One can certainly see, in general terms, how the kinds of cooperative advantages identified by Sotala might provide succour for the proponent of the Doomsday Argument, or how self-improvement advantages of the sort listed could support the Explosion Thesis, but it looks like more work would need to be done to make the case for either fully persuasive (though the former looks in better shape). After all, it must not only be shown that AI+s will have decisive advantages over human beings, but that that those advantages are of the right kind, i.e. the kind that could lead to a recursive intelligence explosion or a doomsday scenario. Still, I think there is plenty to work off in this article for those who want to support either position.
Wednesday, February 13, 2013
Is human enhancement disenchanting? (Part Two)

(Part One)
This is the second part in a brief series looking at whether human enhancement — understood as the use of scientific knowledge and technology to improve the human condition — would rob our lives of meaning and value. The focus is on David Owens’s article “Disenchantment”. The goal is to clarify the arguments presented by Owens, and to subject them to some critical scrutiny.
I started the last day by developing a basic argument in favour of enhancement. This was the Desire Fulfillment Argument (DFA). In essence, it held that enhancement is welcome because it helps us to get what we want. It does so by removing certain obstacles to desire fulfillment. After formalising this argument, I presented Owens’s main critique of it. Owens’s presented his critique in the form of a thought experiment — called the Pharmacy of the Future thought experiment — which depicted a hypothetical future in which every human desire, emotion and mood is manipulable through psychopharmacological drugs.
The suggestion at the end of this thought experiment was that the future being depicted was not welcoming. Indeed, that it would deprive us of the very things needed in order to live a fulfilling life. The question before us now is whether this is the right conclusion. I try to answer that question in the remainder of this post.
I do so in two main parts. First, I formalise the argument underlying the Pharmacy of the Future thought experiment. As you shall see, I present two different versions of the argument, the first focusing on the “confusing” nature of enhancement, the second on its ability to eliminate “fixed points of reference”. Though they are closely related in Owens’s analysis, they are also importantly different. Second, following this, I will offer some critical comments about the two versions of the argument.
1. The Disenchantment Argument
Since Owens’s article is officially titled “Disenchantment”, I have decided to call the formal version of his anti-enhancement argument “The Disenchantment Argument”, however this title is apt to raise questions because there is no serious attempt to offer a formal definition of “disenchantment” is Owens’s article, nor is there an attempt to identify the necessary and sufficient conditions for experiencing disenchantment. Clearly, the term is intended to refer to the reduction or elimination of valuableness, worthwhileness or meaningfulness in life, but beyond that further detail is lacking. Nevertheless, the title seems appropriate (despite its vagueness) and we can get some sense of what disenchantment (in the specific context of Owens’s article) means by reading between the lines.
This begins by trying to reconstruct the logic of the argument underlying the Pharmacy of the Future. Owens says certain things by way of summing up the significance of his thought experiment, and I reproduce some of the key passages here (page references are to the online version of the article, not the published version). From these passages we should be able to reconstruct the argument.
We start with this comment:
You thought you had made a decision and that science would enable you to implement that decision. Instead, science seems to be putting obstacles in the way of your taking any decision at all. The pharmacist is giving you too much choice, more choice than you can think of any grounds for making. By insisting that you take nothing as given, that you regard every aspect of your character as mutable, as subject to your will, the pharmacist puts you in an irresolvable quandary. You can’t handle such total control. (p. 13)
In this passage, Owens’s is decrying the confusion stoked by enhancement technologies: if we can adjust every aspect of our characters, we will become confused and unsure about what to do. The effect will be disorienting, not desire-fulfilling. Underlying this is the notion that the removal of fixed reference points is, in some sense, a bad thing. This idea is more clearly expressed in a later passage:
My worry is not that a successful science of the human mind will deprive us of the ability to take decisions by subjecting us to the immutable facts of our nature and situation [determinism], but rather that it threatens to remove the fixed points that are needed to make decision making possible at all. I feel not constrained but vertiginous. In a purely scientific picture of man, there is no obstacle to indefinite transformation of both self and environment. (p. 14)
Here the concern is not primarily with the possibility of confusion, but with the removal of standards of fixed points of reference. Earlier in the article (p 13 again), Owens links this directly to the fixity of character. In other words, he says the problem with the science of enhancement is that by making everything manipulable, it will gnaw away at, and gradually erode, your sense of self. And since your sense of self is a fixed point of reference, one which you refer to in making choices about your life, anything that undermines it can’t be good for you. This is for the very simple reason that it removes “you” from the picture.
Although the concepts and concerns present in both of the quoted passages are very similar, they do suggest to me two distinct versions of the disenchantment argument. The first works from the claim that enhancement sows the seeds of confusion, offering us a bewildering array of choice. The second works from the claim that enhancement removes the fixed points that are necessary for meaningful decision-making. Hopefully, my reasons for treating these as distinct arguments will become clear in due course. For now, let me present more formal versions of the arguments, starting with the confusion version:
(6) In order for us to derive meaning and value from our decisions, we must actually know what it is we want to achieve from those decisions; we must not be confused about what we want.
- (7) Enhancement renders every aspect of our character (our desires, moods, abilities, etc.) contingent and manipulable.
- (8) If every aspect of our character is contingent and manipulable, then we will no longer know what we want to achieve from our decisions, i.e. we will be confused.
- (9) Therefore, enhancement confuses us. (7, 8)
- (10) Therefore, enhancement robs us of meaning and value. (6, 9)
The second version of the argument follows this exact pattern, merely replacing premises (6) and (8) with the following analogues (and then modifying (9) accordingly):
- (6*) In order for us to derive meaning and value from our decisions, we must have some fixed points of reference, i.e. standards that we hold constant in deciding what to do.
- (8*) If every aspect of our character is contingent and manipulable, then we will no longer have fixed points of reference which act as standards to guide our decision making.
These formalisations are my own interpolation into the text of Owens’s article, and those who have read the article may think I’m being unfair to him. If so, I would be happy to hear suggestions for changing the argument. Nevertheless, I think I’ve been reasonably generous to what he has said. Contrariwise, those who have not read the article, and look now at my formalisations may think the arguments are pretty odd (or weak). Certainly, I can imagine a flood of objections occurring to someone encountering them for the first time. In the final section of this post, I want to sketch out some of the possible objections one could mount. My discussion is a preliminary exploration of the counter-arguments, part of an ongoing project analysing the arguments of those who think enhancement would make life less worthwhile, and so I would welcome suggestions on other possible responses to these arguments (or, indeed, defences of these arguments).
2. General Comments and Criticisms
Allow me start by considering the one premise that is common to both versions of the argument. This is premise (7). You may think it a vast overstatement to claim that “every” aspect our characters will become manipulable, but it does seem to fairly capture what Owens actually says about the prospects for a completed science and technology of human enhancement. You can see this in the above-quoted passages when he talks about “every aspect of your character” being regarded as mutable, and when he says that “[i]n a purely scientific picture of man, there is no obstacle to indefinite transformation of both self and environment.”
Fair though it may be, it offers an obvious point of contestation. Certainly, if our concern is with current enhancement technologies, or even with enhancement technologies that are likely within the 10-20 years, I think the premise is probably false. Not every aspect of our characters is mutable with current technologies — far from it — and may not be anytime soon. There could well be hard limits to manipulability that we will run into in the future.
Interestingly, though premise (7) is a purely factual claim, I don’t think objecting to it only undermines the factual basis Owens’s argument. I think it strikes to its principled and normative core. You see, the thing is, Owens himself concedes that some manipulability of character and desire is acceptable, perhaps even welcome. For instance, in his article he discusses cases of people trying to manipulate their desires in order to overcome weakness of the will or to change habits. In these cases, Owens seems to suggest that the manipulation doesn’t have a disenchanting effect. But if that is true, it seems to set up an easy analogy for the defender of enhancement: if it is desirable in those cases, why isn’t it desirable through the use of more advanced enhancement technologies? In order to block this analogy, Owens needs to claim that the kind of manipulability that would be involved with such technologies is radically distinct from those currently used in overcoming akrasia. If he can’t make that claim, then his argument loses a good deal of its attraction.
But let’s set objections to premise (7) to one side for now, and focus on the two different versions of the argument, starting with the confusion version. First, we need to ask ourselves if the motivating premise is true. In other words, is it true that being confused somehow deprives us of meaning and value? Well, once again, we run into the question of how radical or extreme the confusion is likely to be. I think it’s pretty clear that occasional confusion is tolerable — unless we’re claiming that life as it is currently lived is meaningless and devoid of value, which doesn’t seem to be Owens’s claim, and which would get us into a different set of arguments. So, only if there is radical or extreme confusion, will this motivating premise hold true.
But even then there is the bigger issue of whether premise (8) is true. I have to confess, the causal connection between enhancement and radical confusion is, to me at any rate, somewhat nebulous. In the Pharmacy of the Future case, the seeds of confusion of are sown by the doctor presenting the patient with more and more choices about how to resolve their romantic difficulties. But this seems psychologically implausible to me. If one entered the doctor’s clinic with the desire to maintain one’s relationship, the mere fact that there were other drugs that could resolve the problem in a different way wouldn’t necessarily lead to confusion. The primary motivating desire would allow you to automatically filter out or ignore certain options. A different example might make this objection more compelling. If someone told me that there was a drug that would give me a tremendous desire for chocolate milk (or any other substance), I wouldn’t suddenly become confused. To create confusion, the choices would have to work with some conflicting set of underlying desires, but those won’t always (or even very often) be present. Many potential manipulations of our character will simply seem undesirable or uninteresting and so we won’t be confused by them.
Responding to the other version of the disenchantment argument would follow along similar lines. Again, the causal connection between radical enhancement and the actual elimination of fixed reference points would be questionable on grounds of human psychology. But there is stronger point to be made in relation to that argument as well. For even if enhancement did remove fixed reference points of character, there may remain other fixed reference points that compensate for this effect. I think in particular of ethical or moral reference points, which would seem to be largely unaffected by enhancement. Indeed, one could make an argument in favour of enhancement on this very ground. Oftentimes, what prevents us from achieving the moral ideal in our behaviour are the fixed vices within our characters. If enhancement could help us to overcome those fixed vices, then where is the problem?
Now, I concede I may understate the likely effect of radical enhancement. It could be that enhancement would have an effect on ethical standards too (e.g. by making people instantly forget painful experiences). But I still think this is a promising line of response.
3. Conclusion
To sum up, many people are ambivalent at the prospects of human enhancement. In his article, Owens traces his own ambivalence to the potentially disenchanting effects of enhancement, which he conceives of in terms of confusion and the removal of fixed points of reference that are necessary for decision-making. Owens presents his case through an imaginative thought experiment involving a hypothetical “Pharmacy of the Future”, which allows us to manipulate our desires and moods through a variety of drugs.
Interesting though it is, I have suggested in this post that there are certain problems with Owens’s underlying argument. For one thing, he may vastly overstate the likely effect of human enhancement. And for another, whatever about his motivating premises, his alleged causal links between radical enhancement and disenchantment can be called into question.
Friday, February 8, 2013
Is human enhancement disenchanting? (Part One)

Although there are some enthusiasts, many people I talk to are deeply ambivalent about the prospects of human enhancement, particularly in its more radical forms. To be sure, this ambivalence might be rooted in human prejudice and bias toward the status quo, but I’m curious to see whether there is any deeper, more persuasive reason to share that unease.
That’s why in this blog post I will be looking at an article by David Owens, entitled “Disenchantment”. The article appeared in an edited collection, Philosophers without Gods, several years back, and was noticeable for its presence in that volume because it did not celebrate or champion the atheistic worldview. Instead, it argued that science, conceived broadly to include both scientific discovery and technological advance, threatened to drain our lives of all meaning and purpose.
There is much to object to in Owens’s article. To my mind, he adopts an overly reductive conception of science (at certain points), and vastly overstates the strength of certain scientific theories (at others). For instance he proclaims “in the last four hundred years, a comprehensive theory of the physical world has been devised”, which is clearly false. Furthermore, the article is not specifically directed at human enhancement per se, but rather at the scientific worldview more generally.
Nevertheless, there is a kernel to the article, one which is specifically directed at the enhancement project, and which does seem to echo concerns and doubts one commonly hears about that project. My goal over the next two blog posts is to try to extract that kernel from Owens’s article, render its argumentative structure more perspicuous, and then subject it to some critical scrutiny.
In the remainder of this post, I shall do two things. First, I shall outline what I take to be a basic pro-enhancement argument, one which seems to be lurking in the background of Owens’s article. Second, I shall outline the key thought experiment Owens uses to support his view — the Pharmacy of the Future thought experiment — and make some interpretive comments about this thought experiment. I shall follow up the next day by extracting two possible arguments that Owens might be making, and critically evaluating the success of each.
1. The Desire-Fulfillment Argument in favour Enhancement
Let’s start with a definition. For the purposes of this series of posts, I will define “enhancement” in the following manner:
Enhancement: The use of scientific knowledge and technical means to manipulate various aspects of the human condition, with the intention of thereby improving/enhancing it.
In different contexts, I might be inclined to use a different more precise definition, but this will do for now. One key thing to note about this definition is the way in which it uses the terms “improving/enhancing” as part of the definition of “enhancement”. This might seem odd, particularly given the fact that “enhancement” is a value-laden term. Since that term is typically thought to mean “makes better” there is danger that the definition prejudges the whole conclusion of the enhancement debate. After all, if enhancement is necessarily something that makes us better, then how could one possibly be against it? The definition given above tries to avoid this problem by talking about the intended effect of the manipulation, not the actual effect. Consequently, the critic is perfectly entitled to challenge the desirability of this kind of enhancement, most obviously by claiming that the actual effect deviates from what is intended, or is far more pernicious than we realise.
Before we get to any arguments like that, however, it is worth briefly sketching out a pro-enhancement argument. This one shall be called the Desire Fulfillment Argument (DFA) and it looks something like this:
- (1) It is good, all things considered, for us to be able to get what we want, (to fulfil our desires).
- (2) There are two things that prevent us from getting what we want: (a) technical obstacles, i.e. we do not have the means to change the world to conform with our desires; and (b) doxastic obstacles, i.e. false and superstitious beliefs prevent us from getting what we want.
- (3) Enhancement removes (or, at least, reduces) both kinds of obstacle.
- (4) Therefore, enhancement helps us to get what we want. (5) Therefore, enhancement is good for us.
We need to clarify various aspects of this argument. Let’s start with premise one and its discussion of what is “good…for us”. This suggests that the argument is couched in terms of what is subjectively good for individual human beings, not necessarily what is objectively good for humanity or the universe as a whole. This is an important limitation of the argument, and one to which we shall return in part two. Nevertheless, formulating the argument in terms of what is subjectively good seems appropriate in this context because Owens’s challenge to enhancement is strictly concerned with the effect of enhancement on individual well-being. Furthermore, confining the premise to subjective good makes it pretty plausible in my mind, and though I accept there may be problems with irrational desires and the like, I don’t think this would defeat the appeal of the proposition that — from my perspective — satisfaction of my desires looks to be a pretty good, dare I say “desirable”, thing.
Premise (2) does not need further elaboration, but premise (3) does. Although it might seem obvious to some that enhancement removes or reduces both kinds of obstacles, others may be less convinced. As a result, it is worth considering the proposed mechanisms of obstacle reduction. Obviously, some of this is necessarily speculative since the necessary enhancement technologies have not yet been invented, but the claim would be something like this: Through a variety of biomedical interventions (pharmacological, electronic etc.) the limitations of the human body and mind can be overcome. Smart drugs, for example, can allow us to concentrate for longer, alter our moods so we are more inclined to enjoy particular tasks, improve our memories and cognitive processing power, and so on. Performance enhancing drugs can help improve strength, stamina, speed, sexual prowess and so forth. And other biotechnological devices can remove inherent limitations of the human body (e.g by turning us into cyborgs). All these interventions would allow us to alter the world so as to conform with our desires with greater facility. While our false beliefs and superstitions are not necessarily effected by this, it might hoped that the scientific advances that go along with these technologies, and some of the cognitive drugs, would tend to improve things on this score too. Thus, enhancement should remove or reduce these obstacles.
If that premise is correct, then the argument would seem to go through. But is it a good argument? Does it give strong reasons for endorsing the project of human enhancement? Owens thinks not, and he uses a pretty elaborate thought experiment to make his point. Let’s look at that next.
2. The Pharmacy of the Future
In the initial stages of his article, Owens seems to accept the basic logic and appeal of the DFA. For instance, when discussing the impact of science on our understanding of the natural world, he appears to welcome the removal of technical and doxastic obstacles. For him, the problem comes when science no longer simply concerns itself with the workings of the external world, but with the workings of the human body too, which is exactly what the enhancement project is interested in. He claims that, far from it being the case that enhancement will liberate us to satisfy more and more of our desires and thereby secure our subjective well-being, enhancement will make our desires and motivations too contingent and revisable, thereby confusing and undermining our sense of well-being.
At least, that’s what I think the argument is. But let’s look at the thought experiment before we continue further with this interpretive exercise.
The Pharmacy of the Future story proceeds through the following steps:
Step One: You are in a reasonably successful relationship. You love your partner and he/she seems to love you. The only problem is that you are beset by constant doubts about their fidelity, and it’s beginning to take its toll. You really want to trust your partner, but you can’t seem to do so. So you go to the doctor for help. She informs that a new drug has come on the market. It’s called Credon, and it will quell your suspicions, and help you to trust your partner. You decide to take it.
Step Two: Before you do so, however, the doctor — wanting you to make an informed decision — tells you about another drug, called Libermine. Libermine is subtly different from Credon. Instead of increasing your level of trust, Libermine simply reduces the amount you care about infidelity. With Libermine, you can continue to harbour doubts about your partner’s fidelity, but you simply won’t care anymore, remaining content in your relationship and willing to tolerate the occasional affair. So maybe you should take that instead?
Step Three: But wait, there’s more! Both Credon and Libermine work from the assumption that you desire a relationship in the first place. That is: they treat your desire to continue to be in a romantic relationship as a fixed point of reference in figuring out the best course of treatment. Why must that be the case? There is another drug — called Solox — that will reduce your need for physical and emotional dependence. With Solox you will no longer feel the need to hitch your wagon to another human being. Instead, you can maintain a wide circle of acquaintances and casual friends, and feel perfectly content with that. That seems like an attractive proposition right? Less dependence on others, who have a tendency to disappoint anyway?
Owens actually continues the story through another step, with another new drug that promises to alter your desires and motivations in important ways, but we needn’t go through that now. The three steps outlined above are enough to get the basic picture. With this thought experiment Owens is suggesting that if the enhancement project delivers on its promises — if virtually every aspect of the human mental architecture becomes manipulable with the help of some biomedical intervention — then we are landed in a strange and disorienting world. Desire-fulfillment is still, prima facie, a good thing (I assume Owens doesn’t challenge this idea), but which desires should be fulfilled? If they are all manipulable, won’t we be landed in the equivalent of a Buridan’s Ass dilemma? Unsure of what to do to, and unsure of what we really want. Wouldn’t that paralyse us, and actually deprive us of the very things we need to make our lives subjectively worthwhile?
Owens wants to push us towards these conclusions. Whether he is right to do so is something we shall consider in part two.
Tuesday, February 5, 2013
WL Craig on Morality and Meaning (Series Index)

I've done quite few posts on William Lane Craig's arguments against morality and meaning in an atheistic universe over the past few years. And although I never intended the posts to form a coherent series, I nevertheless thought it might be worth collating and indexing them in this post. So here it is, all the posts I've ever written on this topic (in roughly chronological order, albeit divided into two subject areas):
(Note: A couple of these posts are only tangentially directed at Craig, but they do discuss ideas or concepts he relies on so I've decided to include them.)
Morality
This is a series about Wes Morriston's article of the same name. The series looks at Craig and Alston's solutions to the Euthyphro dilemma. This was an early attempt to get to grips with this issue, probably surpassed by some of my later efforts.
2. Some Thoughts on Theological Voluntarism
This was a post I wrote in response to the Craig-Harris debate way back in Spring 2011. Although prompted by that debate, the post tried to give a decent introduction to theological voluntarism and to highlight a possibly neglected critique of that view, one that Harris could have used in the debate.
As part of his moral argument for the existence of God, Craig appeals to the notion of objective moral values and duties. But what exactly does he mean by saying they are "objective"? This series subjects the crucial passages in Reasonable Faith to a close textual and philosophical analysis. It also suggests a general methodology for determining the merits of any metaethical theory.
4. God and the Ontological Foundation of Morality
Craig insists that only God can provide a sound ontological foundation for objective moral values and duties. Is this right? With the help of Wes Morriston (once again) I try to answer that question in the negative.
In his efforts to avoid the revised Euthyphro dilemma, Craig sometimes relies on William Alston's analogy of the metre stick. According to this analogy, God stands in the same relation to the "Good" as the model metre stick stands in relation to the length "one metre". Does that make any sense? Jeremy Koons argues that it doesn't and in this series of posts I walk through the various steps of Koons's argument.
6. Is Craig's Defence of the Divine Command Theory Inconsistent?
Erik Wielenberg has recently argued that Craig's defence of the DCT is fatally inconsistent. This series looks at Wielenberg's arguments, but also goes beyond them in certain important respects by trying to address the deeper metaphysical reasons for the inconsistency.
7. William Lane Craig and the "Nothing But" Argument
Craig sometimes argues that on the atheistic view humans are nothing but mere animals or collections of molecules, and that this thereby robs humans of moral significance. Can this really be a persuasive objection to atheistic morality? Using the work of Louise Antony, I argue that it can't.
8. William Lane Craig and Ultimate Accountability
Craig believes that the absence of any ultimate accountability for immoral behaviour is a mark against an atheistic account of morality. Again, with the help of Louise Antony, I suggest that this is not the case.
9. Is there a defensible atheistic account of moral value?
Craig and his co-author JP Moreland have argued that atheism has serious problems accounting for the existence of moral values. Wielenberg counters by arguing that there is a defensible atheistic account of value, and this account is no worse off than Craig and Moreland's preferred account of moral value.
Meaning in Life
I've written substantially less about this topic, but I'll add what I have done to the mix anyway. It might be of interest to someone.
1. Craig and Nagel on the Absurd
This was an early podcast I did comparing Craig and Nagel's arguments about the absurdity of life in an atheistic universe. Remember when I used to do podcasts? Maybe I should try again someday?Pa
2. Theism and Meaning in Life
A core tenet of Craig's worldview is that life in a godless universe would be devoid of meaning, purpose and value. With the help of Gianluco Di Muzio's article on this topic, this series of posts tries to do two things. First, it tries to clarify the logic of Craig's arguments against meaning in a godless universe; and second it tries to present an alternative, Godless conception of meaning that avoids Craig's criticisms.
Friday, February 1, 2013
The Golem Genie and Unfriendly AI (Part Two)
 |
| The Golem, by Philippe Semeria |
(Part One)
This is the second (and final) part in my series looking at the arguments from Muehlhauser and Helm’s (MH’s) paper “The Singularity and Machine Ethics”.
As noted in part one, proponents of the Doomsday Argument hold that if a superintelligent machine (AI+) has a decisive power advantage over human beings, and if the machine has goals and values that are antithetical to the goals and values that we human beings think are morally ideal, then it spells our doom. The naive response to this argument is to claim that we can avoid this outcome by programming the AI+ to “want what we want”. One of the primary goals of MH’s paper is to dispute the credibility of this response. The goal of this series of blog posts is to clarify and comment upon the argument they develop.
Part one accomplished most of the necessary stage-setting. I shan’t summarise its contents here. Instead, I simply note that we ended the previous post by adopting the following formulation of the naive response to the Doomsday Argument.
- (5*) We could (easily or without too much difficulty) programme AI+ to have (the best available) moral goals and values, or follow (the best available) moral rules.
- (6*) If AI+ had (the best available) moral goals and values, or followed (the best available) moral rules, it would not be “unfriendly”.
- (7*) Therefore, the unfriendliness thesis is false (or at least the outcome it points to is avoidable).
While this argument is more elaborate than the one presented in MH’s paper, I argued in part that it is preferable for a number of reasons, including the fact that it still retains an air of naivete. The naivete arises out of the two core premises of the argument, i.e. the claim that it would be “easy” to program AI+ to adopt the best available set of moral goals or follow the best available set of moral rules, and the claim that the best available set of moral goals and rules would not be “unfriendly” (where this must be understood to mean “would not lead to disastrous or unwelcome consequences”). MH dispute both claims. They do so by thinking about the two methods AI researchers could use to ensure that the AI+ has a set of moral values or follows a set of moral rules. They are:
The Top-Down Method: The AI researcher directly programmes the values and rules into the AI+. In other words, the researcher painstakingly codes into the AI+ the optimization algorithm(s) which represent the best available conception of what is morally valuable, or codes the AI+ to follow the best available and fully-consistent set of moral rules.
The Bottom-up Method: A sophisticated learning machine with basic goals is created, which is then encouraged to learn moral values, goals and rules on a case-by-case basis (*roughly* similar to how humans do it).
As MH see it, thinking about the plausibility of the first method will call premise (6*) of the naive response into doubt; and thinking about the plausibility of the first method will call premise (5*) into doubt.
In the remainder of this post, I want to consider both of these arguments. I start by addressing MH’s critique of the top-down method, and follow this by considering their critique of the bottom-up method. I close with some general comments about standards of success of philosophical argumentation and their connection to the study of AI+. I do so because reflecting on MH’s arguments (particularly the first one) raises this issue in my mind.
1. The Counterexample Problem and the Top-Down Method
In critiquing the top-down method, MH highlight a common and annoying feature of philosophical argumentation. Take any particular phenomenon of philosophical interest, for example, causation (MH pick knowledge initially but hey what’s wrong with a little variation?).
How does philosophical research about a phenomenon like causation proceed? Typically, what happens is that some philosopher will propose an account or analysis of “causation”. That is to say, they will try to identify exactly what it is that makes one event cause another (say, temporal precession). This account will get tossed about by the philosophical community and, invariably, along will come another philosopher who will pose a counterexample to that particular account. Thus, they will identify a case in which A does not temporally precede B, but nevertheless it is clearly the case that event A is causing B. This might result in a new account of causation being developed, which will in turn be challenged by another counterexample. The process can cycle on indefinitely.
This pattern is common to many fields of philosophical inquiry including, most disconcertingly, philosophical attempts to identify the best available moral values and rules. So, for example, a philosopher will start, often with great enthusiasm, by developing an account of the “good” (e.g. conscious pleasure). This is batted around for a while until someone comes up with a counterexample in which the maximisation of conscious pleasure actually looks to be pretty “bad” (e.g. Nozick’s experience machine argument). This leads to a newer, more refined and sophisticated account of the good, which is then in turn knocked down by another counterexample.
MH exploit this common feature of philosophical argumentation in their critique of the top-down method. For when you think about it, what would an AI programmer have to do when programming an AI+ with a set of moral values or rules? Well, if they wanted to get the “best available” values and rules, presumably they’d have to go to the moral philosophers who have been formulating and refining accounts of moral values and rules for centuries now. They would then use one or more of these accounts as the initial seed for the AI+’s morality. But if every account we’ve developed so far is vulnerable to a set of counterexamples which show that abiding by that account leads to disastrous and unwelcome outcomes, then there is a problem. AI+ will tend to pursue those values and follow those rules to the letter, so it becomes highly likely (if not inevitable) that they will bring about those disastrous consequences at some point in time.
That gives us all we need to formulate MH’s first argument against the naive response, this one being construed as a direct attack on premise (6*):
- (8) If the best available set of moral values or rules has disastrous implications when followed strictly, then it is likely that an AI+ will bring about a world which realises those disastrous implications.
- (9) The best available accounts of moral values and rules have at least one (if not more) disastrous implications when followed strictly.
- (10) Therefore, even if AI+ has the best available moral values or follows the best available moral rules it is still likely to be unfriendly.
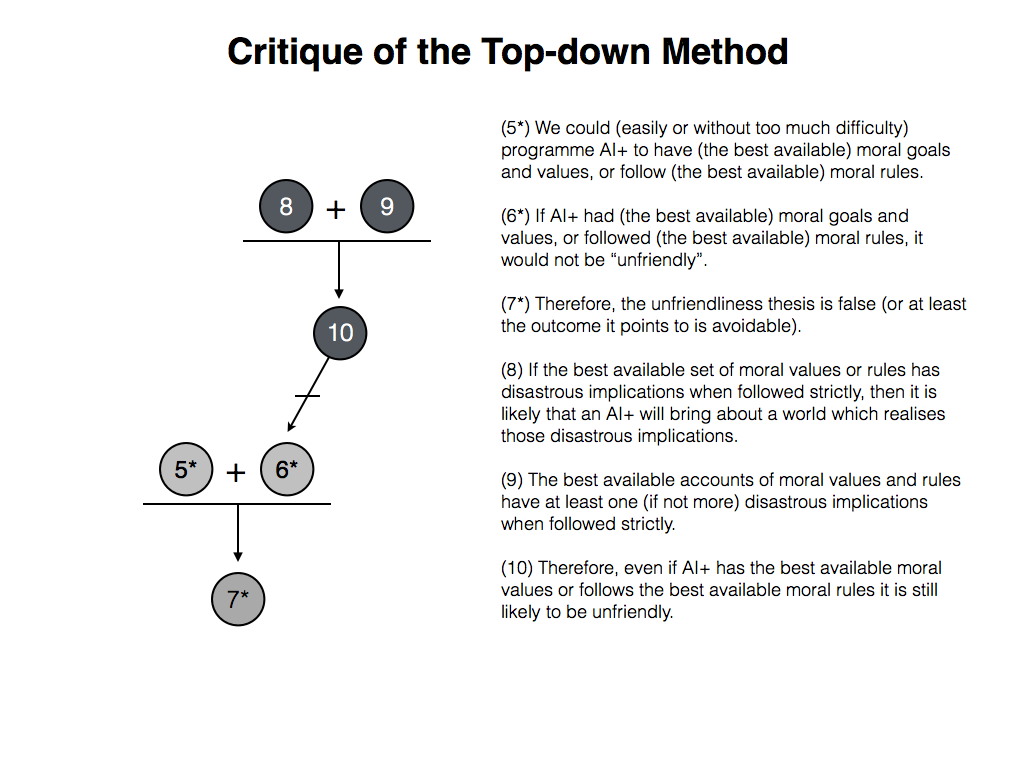
I’m going to look at MH’s defence of premise (9) in a moment. Before doing that, it’s worth commenting briefly on the defence of premise (8). I’ve adumbrated this already, but let’s make it a little more explicit. The defence of this premise rests on two assumptions about the properties that AI+ are likely to have. The properties are: (a) literalness, i.e. the AI+ will only recognise “precise specifications of rules and values, acting in ways that will violate what feels like “common sense” to humans” (MH, p. 6); and (b) superpower, i.e. the AI+ will have the ability to achieve its goals in highly efficient ways. I have to say, I don’t know enough about how AI is in fact programmed to say whether the literalness assumption is credible, and I’m not going to question the notion of “superpower” here. But it is possible that these assumptions are misleading. I haven’t read all of his work on this topic, but Alexander Kruel suggests in some of his writings that arguments from the likes of MH (where “likes of” = “members of research institutes dedicated to the topic of AI risk”) tend to ignore how AI programming is typically carried out and thus tend to overstate the risks associated with AI development. I’m not sure that this critique would directly challenge the literalness assumption, but it might suggest that any AI which did counterintutive things when following rules would not be developed further. Thus, the risks of literalness are being overstated.
2. Do all moral theories have (potentially) disastrous implications?
Let’s assume, however, that premise (8) is fine. That leaves premise (9) as the keystone of the argument. How does it stack up? The first thing to note is that it is nigh on impossible to prove that every single account of moral values and rules (that has been or might yet be) is vulnerable to the kinds of counterexamples MH are alluding to. At best, one can show that every theory that has been proposed up until now is vulnerable to such counterexamples, but even that might be asking too much (especially since MH want to be optimistic about the potential of ideal preference theories). So examining a representative sample of the theories that have been proposed to date might be more practical. Further, although it wouldn’t provide rock-solid support for premise (9), doing so might provide enough support to make us think that the naive response is indeed naive, which is all we really wanted to do in the first place.
Unsurprisingly, this is what MH do. They look at a few different examples of utilitarian accounts of moral value, and show that each of these accounts is vulnerable to counterexamples of the sort discussed above. They then look (more generally) at rule-based moral theories, and show how these could have several implementation problems that would lead to disastrous consequences. This provides enough basic support for premise (9) to make the naive response look sufficiently naive. I’ll briefly run through the arguments they offer now, starting with their take on hedonic utilitarianism.
Hedonic utilitarianism holds, roughly, that the most valuable state of being is the one in which conscious pleasure is maximised (for the maximum number of people). Although this theory is vulnerable to a number of well-known counterexamples — e.g. Parfit’s repugnant conclusion or Nozick’s experience machine — MH note a very important problem with it from the perspective of AI programming. The term “pleasure” lacks specificity. So if this account of moral values is going to be used to seed an AI+’s morality, the programmer is going to have to specify exactly what it is that the AI+ should be maximising. How might this pan out? Here are two possible accounts of pleasure which have greater specificity. In discussing each, counterexamples which are consistent with those accounts will be presented:
Pleasure gloss theory: According to MH, the growing consensus in neurobiology is that what we refer to as pleasure is not actually a sensation, but rather a gloss added to our sensation patterns by additional brain activity. In essence, pleasure is something that the brain “paints” onto sensations. What kinds of counterexamples would this account of pleasure be vulnerable to? MH suggest that if pleasure can simply be painted onto any sensations whatsoever, an AI+ might be inclined to do this rather than seek out sensations that are typically thought to be pleasurable. This could by hooking them up to some machines or implanting them with nanotechnology that activates the relevant “pleasure painting” areas of the brain, in a scenario much like Nozick’s experience machine. This would be a logically consistent implication of the hedonic theory but an unwelcome one.
Reward Signal Theory: Alternatively, one could specify that pleasure is anything that functions as a reward signal. Would that create problems? Well, if reward signals can be implemented digitally or mechanically, the AI+ might simply manufacture trillions of digital minds, and get each one to run its reward signal score up to the highest possible number. This would achieve the goal of maximises hedonic pleasure.
So adding specificity can still lead to disastrous consequences for hedonic utilitarianism. Not a particularly surprising conclusion given the general status of such theories in moral philosophy, but one worth spelling out in any event.
How about negative utilitarianism, which holds that instead of maximising conscious pleasure one should minimise suffering, is that vulnerable to counterexamples as well? Presumably, there are specification problems to be dealt with here again, but more generally the problem is that the quickest route to the minimisation of suffering would seem to be to kill all humans. After all, no humans means no suffering. An AI+ might be inclined to follow the quickest route. But wait, couldn’t this be avoided by simply adding an exception clause to the AI+’s program stating that that the AI+ should minimise suffering, provided doing so doesn’t involve killing humans? Maybe, but that would run into the difficulties faced by rule-based theories, which I’ll be talking about in a moment.
The final utilitarian theory addressed by MH is preference/desire utilitarianism. According to this theory, the goal should not be to maximise conscious pleasure but, rather, to maximise the number of human preferences/desires that are satisfied. Would this run into problems? MH say it would. According to several theories, desires are implemented in the dopaminergic reward system in the human brain. Thus, one way for an AI+ to achieve the maximum level of desire satisfaction would be to rewire this system so that desires are satisfied by lying still on the ground.
Isn’t that a little far-fetched? MH submit that it isn’t, certainly no more far-fetched than suggesting that the AI+ would achieve the maximum level desire satisfaction by created a planet-wide utopia by satisfying the desires that humans actually have. This is for two reasons. First, individual human beings have inconsistent preferences, so it’s not clear that this could maximised desire-satisfaction could be implemented at an individual level without some re-wiring. Second, humans interact in “zero sum” scenarios. This means it will not be possible to satisfy everybody’s desires (e.g. as when two people have the desire to win some competition that can only have one winner). This makes the “lying still on the ground” scenario more plausible.
That’s all MH have to say about utilitarian theories of value. What about rule-based accounts of morality? Do they fare any better? Without discussing specific examples of rule-based accounts, MH identify several general problems with such accounts:
- If there are several rules in the theory, they can conflict in particular cases thereby leading to at least one being broken.
- The rules may fail to comprehensively address all scenarios, thereby leading to unintended (and unknown) consequences.
- An individual rule might have to be broken in a particular case where the machine faces a dilemmatic choice (i.e. a choice in which it must, by necessity, break the rule by opting for one course of action over another).
- Even if a set of rules is consistent, there can be problems when the rules are implemented in consecutive cases (as allegedly shown in Petit 2003).
- Rules may contain vague terms that will lead to problems when greater specificity is added, e.g. the rule “do not harm humans” contains the vague term “harm”. These are similar to the problems mentioned above with respect to hedonic utilitarian theories.
- If the rules are external to the AI+’s goal system, then it is likely to exploit loopholes in the rules in order to make sure it can achieve its goals (much like a lawyer would do only to a greater degree).
Thus, the claim is that rule-based theories are vulnerable to the same kinds of problems as value-based theories. Although I accept this basic idea, I think some of these problems are less concerning than others. In particular, I do not really think the fact that an AI+ might face a moral dilemma in which it has to break a moral rule is problematic. For one thing, this might simply lead to a Buridan’s Ass type of situation in which the machine is unable to decide on anything (those more knowledgeable about AI can correct me if I’m wrong). Or, even if there is some trick used to prevent this from happening and the AI+ will follow one course of action, I do not see this as being morally concerning. This is because I think that in a true moral dilemma there is no wrong or right course of action, and thus no way to say we would be better off following one course of action or another.
3. The Critique of the Bottom-up Method
So much for MH’s critique of the top-down method. We can now consider their critique of the bottom-up method. As you recall, the bottom-up method would require the AI+ to learn moral values and rules on a case-by-case basis, presumably a method that is somewhat analogous to the one used by human beings. Superficially, this might seem like a more reassuring method since we might be inclined to think that when rules and values are learned in this way, the machine won’t act in a counterintuitive or unexpected manner.
Unfortunately, there is no good reason to think this. MH argue that when a machine tries to learn principles and rules from individual cases, we can never be 100% sure that they are extrapolating and generalising the “right” rules and principles. In support of this contention, they cite a paper from Dreyfus and Dreyfus (notorious critics of AI) published back in 1992. In the paper, Hubert and Stuart Dreyfus cite a case in which the military tried to train an artificial neural network to recognise a tank in a forest. Although the training appeared, on initial tests, to be a success, when the researchers tried to get the network to recognise tanks in a new set of photographs, it failed. Why was this? Apparently, the system had only learned to recognise the difference between a network with shadows and without; it had not learned to recognise tanks. The same problem, MH submit, could apply to learning moral values and rules: unless they are explicitly programmed into the AI, we can never be sure that they have been learned.
In addition to this problem, there is the fact that a superintelligent and superpowerful machine is likely to bring about states of affairs which are so vastly different from the original cases in which it learned its values and rules that it will react in unpredictable and unintended ways. That gives us this argument:
- (11) If an AI+ learns the wrong moral values and rules from the original set of cases it is presented with, or if it is confronted with highly disanalogous cases, then unintended, unpredictable, and potentially disastrous consequences will follow.
- (12) It is likely (or certainly quite possible) that an AI+ will learn the wrong values and rules from the original set of cases, or will bring about states of affairs that are vastly different from those cases.
- (13) Therefore, even if AI+ learns moral values and goals on a case-by-case basis, it is likely that unintended, unpredictable, and potentially disastrous consequences will follow.

I haven’t got too much to say about this argument. But three brief comments occur to me. First, the argument is different from the previous one in that it focuses more on the general uncertainty that arises from the bottom-up method, not on particular hypothetical (but logically consistent) implications of the best available moral values and rules. Second, I don’t really know whether this is a plausible argument because I don’t know enough about machine learning to say whether the problems highlighted by Dreyfus and Dreyfus are capable of being overcome. Third, elsewhere in their article, MH discuss the fact that human brains have complex, sometimes contradictory, ways of identifying moral values and following moral rules. So even if we tried to model an AI+ directly on the human brain (e.g. through whole-brain emulation), problems are likely to follow.
4. Conclusion
To sum up, the naive response to the Doomsday Argument is to claim that AI+ can be programmed to share our preferred moral values or to follow moral rules. MH argue that this response is flawed in two main respects. First, there is the problem that many of our moral theories have disastrous implications in certain scenarios, implications that an AI+ might well be inclined to follow because of their literal mindedness. Second, there is the problem that training AI+ to learn moral values and rules on a case-by-case basis is likely to have unintended and unpredictable consequences.
One thing occurred to me in reading all this (well, several things actually but only one that I want to mention here). This has to do with standards of success in philosophical argumentation and their applicability to debates about friendly and unfriendly AI. As many people know, philosophers tend to have pretty high standards of success for their theories. Specifically, they tend to hold that unless the theory is intuitively compelling in either all logically, metaphysically or physically possible worlds, it is something of a failure. This is why supposedly fatal counterexamples are so common in philosophy. Thus, an account of knowledge is posed, but it is found not to account for knowledge in certain possible scenarios, and so the account must be refined or abandoned.
Advocates of the Doomsday Argument employ similarly high standards of success in their discussions. They tend to argue that unless disastrous consequences for an AI+ can be ruled out in all (physically) possible worlds, the Doomsday Argument is correct. This means they rely on somewhat farfetched or, at least, highly imaginative hypotheticals when defending their view. We see this to some extent in MH’s first argument against the naive response. But the question arises: Are they right to employ those high standards of success?
I think I can see an argument in favour of this — roughly: since an AI+ will be vastly powerful it might be able to realise all physically possible worlds (eventually); so we have to make sure it won’t do anything nasty in all physically possible worlds — but I’d like to leave you with that question since I believe it’s something that critics of the Doomsday Argument tend to answer in the negative. They charge the doom-mongers with being too fanciful and outlandish in their speculations; not grounded enough in the realities of AI research and development.
Subscribe to:
Posts (Atom)