 |
| Google's Self-Driving Car - via Becky Stern on Flickr |
Swerve or slow down? That is the question. The question that haunts designers of self-driving cars. The dilemma will be familiar to students of moral philosophy. Suppose an autonomous car is driving down an urban street. You are the passenger. Suddenly, from behind a parked car, a group of pedestrians stumbles out into the middle of the road. If the car breaks and continues on its current course, it will not slow down in time to avoid colliding with the group. If it does collide with them, it will almost certainly kill them all. If the car swerves, it will collide with a solid wall, almost certainly killing you. What should it be programmed to do?
Some philosophical thought experiments are completely fanciful — the infamous trolley problems upon which this story is based are good examples of this. This particular philosophical thought experiment is not. It’s likely that self-driving cars will encounter some variant of the swerve or slow down dilemma in the course of their operation. After all, human drivers encounter these dilemmas on a not infrequent basis. And no matter how safe and risk averse the cars are programmed to be, they will have unplanned encounters with reckless pedestrians.
So what should be done? The answer is that the car should be programmed to follow some sort of moral algorithm — a rule (or set of rules) that tells it how to behave in these scenarios. One possibility is that it should be programmed to follow an act-utilitarian algorithm: the probability of death for you and the pedestrians should be calculated (the car could be fed the latest statistics about deaths in these kinds of scenarios and update accordingly), and it should pick the option that maximises the overall survival rate. Alternatively, the car could be programmed to follow a ‘heroic self-sacrifice’ algorithm, i.e. whenever it encounters a scenario like this, it should sacrifice the car and its passenger, not the pedestrians. Either way, the same outcome is likely: the car should swerve, not slow down. More selfish algorithms are possible too. Maybe the car should follow a ‘Randian algorithm’ whereby the interests of the driver trump the interests of the pedestrians?
In this post, I want to look at yet another possible algorithm that could be adopted in the swerve or slow down dilemma: a Rawlsian one. This is a proposal that has recently been put forward by Derek Leben, a philosopher at the University of Pittsburgh. I find the proposal fascinating because not only is it philosophically interesting, it also sounds eminently feasible. At the same time, it forces us to confront some uncomfortable truths about ethics in the age of autonomous vehicles.
I’ll break the discussion down into three parts. First, I’ll briefly explain Rawlsianism - the philosophy that inspires the algorithm. Second, I’ll outline how a Rawlsian algorithm would work in practice. And third, I’ll address some of the objections one could have to the use of the Rawlsian algorithm. This post is very much a summary of Leben’s article, which I encourage everyone to read. It’s one of the more interesting pieces of applied philosophy that I have read in recent times.
1. What is a Rawlsian Algorithm?
Leben’s proposal is obviously based on the work of John Rawls, who was the most influential political philosopher of the 20th century. Rawls’s most famous work was the 1971 classic A Theory of Justice in which he outlined his vision for a just society. We don’t need to get too mired in the details of the theory for the purposes of understanding Leben’s proposal; a few choice elements are all we need.
First, we need to appreciate that Rawls’s theory is a form of liberal contractarianism. That is to say, Rawls works from the basic liberal assumption that people are moral equals (i.e. no one person has the right to claim moral authority over another without certain legitimacy conditions being met). This moral assumption creates problems because we often need to exercise some coercive control over one another’s behaviour in order to secure mutually beneficial outcomes.
This problem is easily highlighted by thinking about some of the classic ‘games’ that are used to explain the issues that arise when two or more people must cooperate for mutual gain. The Prisoners’ Dilemma is the most famous of these. The set-up will be familiar to many readers (if you know it, skip this paragraph and the next). Two prisoners are arrested for the same crime and put in separate jail cells. The police are convinced that they have enough evidence to charge them with an offence that attracts a two year sentence, however, they would like to charge at least one of them with a more severe offence that attracts a ten year sentence. To enable this, the police offer each prisoner the same deal. If one of them ‘squeals’ on their partner and the partner remains silent, they can get off free and the partner will be charged with the ten-year offence. If they both squeal on each other, they both get charged with a five-year offence. If they both remain silent, they will be charged with the two-year offence. If you were one of these prisoners, what would you do? Before answering that, take a look at the payoff matrix for the game, which is illustrated below. The strategies of ’squealing’ and ’staying silent’ have been renamed ‘defect’ and ‘cooperate’ in keeping with the convention in the literature.
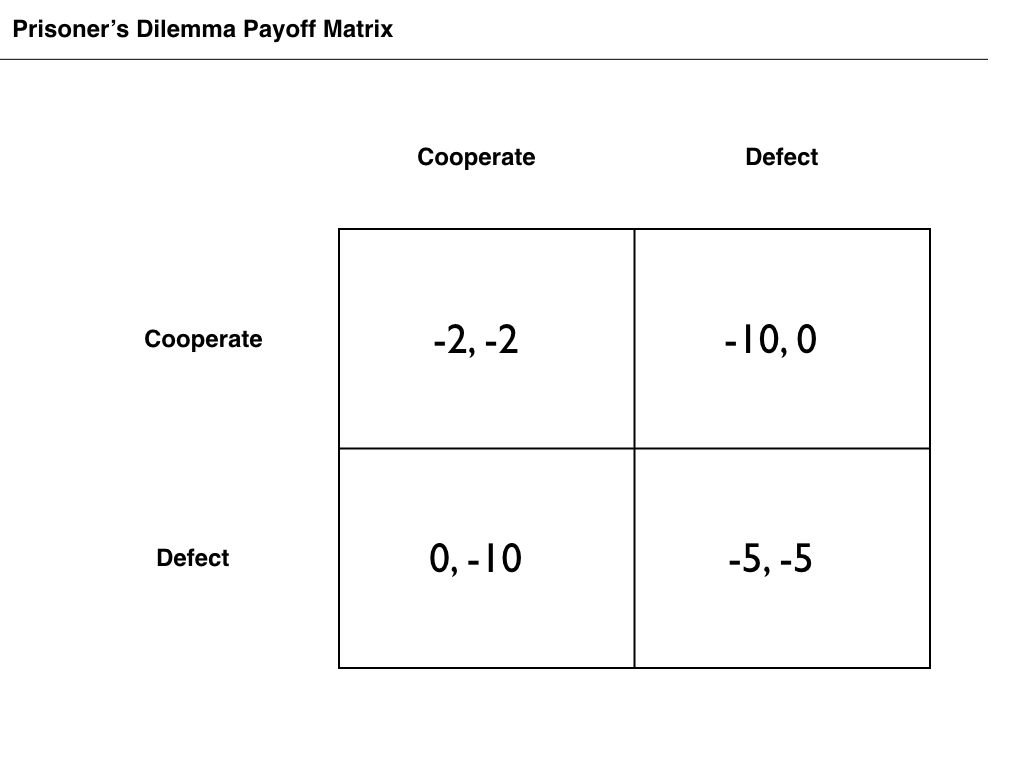
So now that you have looked at the payoff matrix, return to the question: what should you do? If we follow strict principles of rationality, the answer is that you should squeal on your partner. In the language of game theory, doing so ‘strictly dominates’ staying silent: it always yields a higher payoff (or in this instance: a lesser sentence), no matter what your opponent does. The difficulty with this analysis, though, is that it yields an outcome that is clearly worse for both prisoners than remaining silent. They both end up in jail for five years when they could have got away with a two-year sentence. In technical terms, we say that the ‘rational’ choice in the game yields a ‘Pareto inefficient’ outcome. There is another combination of choices in the game that would make every player better off without a loss to anyone else (an outcome that is ‘Pareto optimal’).
The Prisoners’ Dilemma is just a story, but the interaction it describes is supposed to be a common one. Indeed, one of Rawls’s key contentions — and if you don’t believe me read his lecture notes on political philosophy — is that coming up with a way to solve Prisoners’ Dilemma-scenarios is central to liberal political theory. Somehow, we have to move society out of the Pareto inefficient outcomes and into the Pareto optimal ones. The obvious way to do this is to establish a state with a monopoly on the use of violence. The state can then threaten people with worse outcomes if they fail to cooperate. But coercive threats don’t sit easily with the liberal conscience. There has to be some morally defensible reason for allowing the state to exercise its muscle in this way.
That’s where the Rawlsian algorithm comes in. Like other liberal theorists, Rawls argued that the authority we grant the state has to be such that reasonable people would agree to it. Imagine that everyone is getting together to negotiate the ‘contract of state’. What terms and conditions would they agree to? One difficulty we have in answering this question is that we are biased by our existing predicament. Some of us are well-off under the current system and will, no doubt, favour its terms and conditions. Others are less well-off and will favour renegotiation. To figure out what reasonable people would really agree to, we need to rid ourselves of these biases. Rawls recommended that we do this by imagining that we are negotiating the contract of state from behind a ‘veil of ignorance’. This veil hides our current predicament from us. As a result, we don’t know where we will end up after the contract has been agreed. We might be among the better off; but then again we might not.
Rawls’s key claim then is that if we were negotiating from behind the veil of ignorance, we would adopt the following decision rule:
Maximin decision rule: Favour those terms and conditions (policies, rules, procedures etc) that maximise the benefits to the worst off members of society.
Or, to put it another way, favour the distribution of the benefits and burdens of social living that ‘raises the floor’ to its highest possible level.
This maximin decision rule is in effect a ‘Rawlsian’ algorithm. How could it be implemented in a self-driving car?
2. The Rawlsian Algorithm in Practice
To implement a Rawlsian algorithm in practice, you need to define three variables:
Players: First, you need to define the ‘players’ in the game in which you are interested. In the case of the swerve or slow down ‘game’ the players are the passenger(s) (i.e. you - P1) and the pedestrians. For ease of analysis, let’s say there are four of them (P2... P5).
Actions: Second, you need to define the actions that can be taken in the game. In our case, the actions are the decisions that can be made by the car’s program. There are two actions in this game: slow down (A1) and swerve (A2)
Utility Functions: Third, you’ll need to define the utility functions for the players in the game, i.e. the payoffs they receive for each action taken. In our case, the payoffs can be recorded as the probability of survival for each of the players. This will be a number between 0 and 1. Presumably, actual tables of data could be assembled for this purpose based on records of past accidents of this sort, but let’s say for our purposes that if the car slows down and collides with the four pedestrians, it lowers their probability of survival from 0.99 to 0.05. And if it swerves, it lowers your probability of survival from 0.99 to 0.01. (Just note that this means we are assuming that the pedestrians have a slightly higher probability of survival from collision in this scenario than the passenger does)
This gives us the following payoff matrix for the game:

With this information in place, we can easily program the car to follow a maximin decision procedure. Remember the goal of this procedure is to ‘raise the floor’ for the highest number of people. This can be done by following three simple steps:
Step One: Identify the worst payoffs for each possible action and compile them into a set. In our case, the worst payoff for A1 is the 0.05 probability of survival and the worst payoff for A2 is the 0.01 probability of death. This gives us the following set of worst outcomes (0.05, 0.01).
Step Two: From this set of worst outcomes, identify the best possible outcome and the actions that yield it. Call this outcome a. In our case, outcome a is the 0.05 probability of survival and the action that yields it is A1.
Step Three: If there is only one action that yields a , implement this action. If there is more than one action that yields a, then you need to ‘mask’ for a (i.e. eliminate the as from the analysis) and repeat steps one and two again (i.e. maximise for the second worst outcome). You repeat this process until either (i) you identify a unique action that can yield an outcome a or (ii) if there is only one outcome left in the game, and a tie between two or more actions that yield that outcome, then you randomise between those actions (because it doesn’t matter from the maximin perspective).
In the case of the swerve or slow down dilemma, the algorithm is very simply applied. Following step two there will be only one action (A1) that yields the least-bad outcome in the game (the 0.05 probability of survival). This is the action that will be selected by the car. This means the car will slow down rather than swerve. This is in keeping with Rawls’s maximin procedure since it is raises the worst possible outcome from a 0.01 probability of survival to a 0.05 probability of survival. This is, admittedly, somewhat counterintuitive because it means that more people are likely to die, but we return to this point below.
The Rawlsian algorithm is illustrated below.
 |
| The Rawlsian Algorithm - diagram from Leben 2017 |
Two points should be noted before we proceed. First, two aspects of this decision-procedure are not found in Rawls’s original writing: (i) the ‘masking’ procedure and the (ii) randomisation option. These are modifications introduced by Leben, but they make a lot of sense and I would not be inclined to challenge them (I’ve long been a fan of randomisation options in the design of moral algorithms). Second, the maximin procedure can yield significantly different outcomes if you modify the probabilities of survival ever so slightly. For example, if you reversed the probabilities of survival so that the pedestrians had the 0.01 probability of survival following collision and the driver had the 0.05, the maximin procedure would favour swerving over slowing down. This is despite the fact that the utilitarian choice in both cases is the same.
3. Objections to the Rawlsian Algorithm
One thing I like about Leben’s proposal is that it is eminently practicable. Sometimes discussions about moral algorithms are fantastical because they demand information that we simply do not have nor could not hope to have. That doesn’t seem to be true here. We could assign reasonable figures to the probability of survival in this scenario that could be quickly calculated and updated by the car’s onboard computer. Furthermore, I like how it puts another option on the table when it comes to the design of moral algorithms. To date, much of the discussion has focused on standard act-utilitarian versus deontological algorithms. This is largely due to the fact that the discussion has been framed in terms of trolley problem dilemmas, which were first invented to test our intuitions with respect to those moral theories.
That said, there are some obvious concerns. One could reject Rawls’s views and so reject any algorithm based on them, but as Leben notes, his job is not to defend Rawlsianism as a whole. That’s too large a task. Other concerns can be tied more specifically to the application of Rawlsianism to the swerve or slow down scenario. Leben discusses three in his article.
The first is that the utility functions are incomplete. The survival probabilities are just one factor among many that we should be considering. Some people would claim that not all lives are equal. Some people are young; some are old. The young have more of their lives left to live. Perhaps they should be favoured in any crash algorithm over the old? In other words, perhaps there should be some weighting for ‘life years’ included in the Rawlsian calculation. Leben points out that, if you wanted to, you could include this information. The QALY (quality adjusted life years) measure is in widespread use in healthcare contexts and could inform the car’s decision-making. It might be a little bit more difficult to implement this in practice. The car would have to be given access to everybody’s QALY score and this would have to be communicated to the car prior to its decision. This is not impossible — given ongoing developments in smart tech and mass surveillance, people could be forced to carry devices on their person that communicated this information to the car — but allowing for it would have other significant social costs that should be borne in mind.
The second is that applying the Rawlsian algorithm might create a perverse incentive. Remember, the maximin decision procedure tries to avoid the worst possible outcomes. This means, bizarrely, that it actually pays to be the person with the highest probability of death in a swerve or slow down dilemma. We see this clearly above: the mere fact that the passenger had a higher probability of death from collision with the wall was enough to save his/her skin, despite the fact that doing so would raise the probability of death for more people. This might give people a perverse incentive not to take precautions to protect themselves from harm on the roads. But this incentive is probably overstated. Even though the kinds of dilemmas covered by the algorithm are not implausible, they are still going to be relatively rare. The benefits of taking precautions in all other contexts are likely to outweigh the costs of doing so when you land yourself in a swerve or slow-down type scenario.
The third and final concern is simply the one I noted above: that the maximin procedure yields a very counterintuitive result in the example given. It says the car should collide with the pedestrians even though this means that more people are likely to die. This is pretty close to a typical utilitarianism vs Rawlsianism concern and so brings us into bigger issues in moral philosophy. But Leben says a couple of sensible things about this. One is that how counterintuitive this is will depend on how much Rawlsian Kool Aid we have imbibed. Rawls argued that we should think about social rules from behind a ‘thick’ veil of ignorance, i.e. a veil that masks us from pretty much everything we know about our current selves, leaving us with just our basic rational and cognitive faculties. If we really didn’t know who we might end up being in the swerve or slow down dilemma, we might be inclined to favour the maximin rule. The other point, which is probably more important, is that every moral rule that is consistently followed yields counterintuitive results. So if we’re after totally intuitive results when it comes to designing self-driving cars, we are probably on a fool’s errand. Still, as I discussed previously when looking at the work of Hin Yan Liu, the fact that self-driving cars might follow moral rules more consistently than humans ever could, might tell against them for other reasons.
Anyway, that's it for this post.
No comments:
Post a Comment