
(Threat of Algocracy - Series Index)
I am really looking forward to Frank Pasquale’s new book The Black Box Society: The Secret Algorithms that Control Money and Information. The book looks to examine and critique the ways in which big data is being used to analyse, predict and control our behaviour. Unfortunately, it is not out until January 2015. In the meantime, I’m trying to distract myself with some of Pasquale’s previously published material.
One example of this is an article that he wrote with Danielle Keats Citron (whose work is also really interesting). The article is entitled “The Scored Society: Procedural Due Process for Automated Predictions”. The article looks at the recent trend for using big data to “score” various aspects of human behaviour. For example, there are now automated “scoring” systems used to rank job applicants based on their social media output, or college professors for their student-friendliness, or political activists for their likelihood of committing crimes. Is this a good thing? Citron and Pasquale argue that it is not, and suggest possible reforms to existing legal processes. In short, they argue for a more robust system of procedural due process when it comes to the use of algorithms to score human behaviour.
In this post, I want to take a look at what Citron and Pasquale have to say. I do so in three parts. First, by looking at the general problem of the “Black Box” society (something I have previously referred to as “algocracy”). Second, by discussing the specific example of a scoring system that Citron and Pasquale use to animate their policy recommendations, namely: credit risk scoring systems. And third, by critically evaluating those policy recommendations.
1. The Problem of the Black Box Society
Scoring systems are now everywhere, from Tripadvisor and Amazon reviews, to Rate my Professor and GP reviews on the NHS. Some of these scoring systems are to be welcomed. They often allow consumers and users of services to share valuable information. And they sometimes allow for productive feedback-loop between consumers and providers of services. The best systems seem to work on either a principle of equality — where everyone is allowed to input data and have their say — or a reversal of an inequality of power — e.g. where the less powerful consumer/user is allowed to push back against the more powerful producer.
But other times scoring systems take on a more sinister vibe. This usually happens when the scoring system is used by some authority (or socially powerful entity) to shape or control the behaviour of those being scored. For example, the use of scoring systems by banks and financial institutions to restrict access to credit, or by insurance companies to increase premiums. The motives behind these scoring systems are understandable: banks want to reduce the risk of a bad debt, insurance companies want enough money to cover potential payouts (and to make a healthy profit for themselves). But their implementation is more problematic.
The main reason for this has to do with their hidden and often secretive nature. Data is collected without notice; the scoring algorithm is often a trade secret; and the effect of the scores on an individual’s life is often significant. Even more concerning is the way in which humans are involved in the process. At the moment, there are still human overseers, often responsible for coding the scoring algorithms and using the scores to make decisions. But this human involvement may not last forever. As has been noted in the debate about drone warfare, there are three kinds of automated system:
Human-in-the-loop Systems: These are automated systems in which an input from a human decision-maker is necessary in order for the system to work, e.g. to programme the algorithm or to determine what the effects of the score will be.
Human-on-the-loop Systems: These are automated systems which have a human overseer or reviewer. For example, an online mortgage application system might generate a verdict of “accept” or “reject” which can then be reviewed or overturned by a human decision-maker. The automated system can technically work without human input, but can be overridden by the human decision-maker.
Human-out-of-the-loop Systems: This is a fully automated system, one which has no human input or oversight. It can collect data, generate scores, and implement decisions without any human input.
By gradually pushing human decision-makers off the loop, we risk creating a “black box society”. This is one in which many socially significant decisions are made by “black box AI”. That is: inputs are fed into the AI, outputs are then produced, but no one really knows what is going on inside. This would lead to an algocracy, a state of affairs in which much of our lives are governed by algorithms.
2. The Example of Credit-Scoring Systems
Citron and Pasquale have a range of policy proposals that they think can deal with the problem of the black box society. They animate these proposals by using the example of credit-scoring algorithms. These algorithms are used to assess an individual’s credit risk. They are often used by banks and credit card companies as part of their risk management strategies.
The classic example, in the U.S., is the Fair, Isaac & Co. (FICO) scoring system. A typical FICO score is a three-digit number that is supposed to represent the risk of a creditor defaulting on a loan. FICO scores range from 300 to 850, with higher scores representing lower risk. They are routinely used in consumer lending decisions in the U.S.. That said, there are other credit scoring systems, many of which became famous during the 2008 financial crisis (largely because they were so ineffective at predicting actual risk).
These scoring systems are problematic for three reasons, each of which is highlighted by Citron and Pasquale:
Opacity Problem: The precise methods of calculation are trade secrets. FICO have released some of the details of their algorithm, but not all of them. This means that the people who are being scored don’t know exactly which aspects of their personal data are being mined, and how those bits of data are being analysed and weighted. This has led to a lot of misinformation, with books and websites trying to inform consumers about what they can do to get a better score.
Arbitrariness Problem: The scores produced by the various agencies seem to be arbitrary, i.e. to lack a consistent, reasoned basis. Citron and Pasquale give two examples of this. One is a study done on 500,000 customer files across three different ratings agencies. This showed that 29% of customers had ratings that differed by more that 50 points across the different agencies, even though all three claim to assess the risk of default. A second example is the fact that seemingly responsible behaviour can actually reduce your score. For example, seeking more accurate information about one’s mortgage — which sounds like something that a responsible mortgagee would do — lowers one’s score.
Discrimination Problem: The scoring systems can be loaded with biasing factors, either because of the explicit biases of the users, or the implicit biases attached to certain datasets. This means that they can often have a disproportionate impact on racial and ethnic minorities (cf Tal Zarsky’s argument). One example of this is the way in which Allstate Insurance (in the U.S.) used credit scores. They were alleged to have used the information provided by credit scores in a discriminatory way against 5 million Hispanic and African-American customers. This resulted in litigation that was eventually settled out of court.
When you couple these three problems with the ineffectiveness of credit rating systems in the lead-up to the financial crisis, you get a sense of the dangers of the black box society. Something should be done to mitigate these dangers.
3. Can we solve the problem?
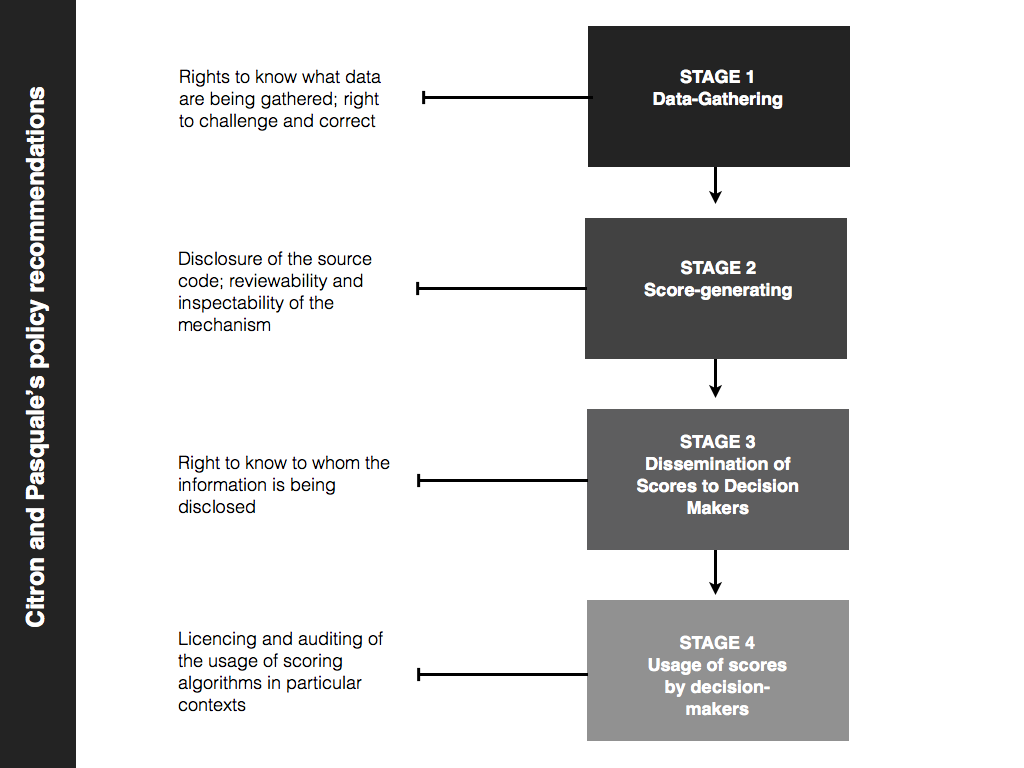
To that end, Citron and Pasquale recommend that we think of the scoring process in terms of four distinct stages: (i) the data gathering stage, in which personal data is gathered; (ii) the score-generating stage, in which an actual score is produced from the data; (iii) the dissemination stage, in which the score is shared with decision-makers; and (iv) the usage stage, in which the score is actually used in order to make some decision. These four stages are illustrated in the diagram below.

Once we are clear about the process, we can begin to think about the remedies. Citron and Pasquale suggest that new procedural safeguards and regulations be installed at each stage. I’ll provide a brief overview here.
First, at the data-gathering stage, people should be entitled to know which data are being gathered; and they should be entitled to challenge or correct the data if they believe it is wrong. The data-gatherers should not be allowed to hide behind confidentiality agreements or other legal facades to block access to this information. There is nothing spectacular in this recommendation. Freedom of information and freedom of access to personal information is now common in many areas of law (particularly when data are gathered by governments).
Second, at the score-generating stage, the source code for the algorithms being used should be made public. The processes used by the scorers should be inspectable and reviewable by both regulators and the people affected by the process. Sometimes, there may be merit to the protection of trade secrets, but we need to switch the default away from secrecy to openness.
Third, at the dissemination stage, we run into some tricky issues. Some recent U.S. decisions have suggested that the dissemination of such information cannot be blocked on the grounds that doing so would compromise free speech. Be that as it may, Citron and Pasquale argue that everyone should have a right to know how and when their information is being disseminated to others. This right to know wouldn’t compromise the right to free speech. Indeed, transparency of this sort actually facilitates freedom of speech.
Fourth, at the usage stage, Citron and Pasquale argue for a system of licencing and auditing whenever the data are used in important areas (e.g. in making employment decisions). This means that the scoring system would have to be licenced for use in the particular area and would be subjected to regular auditing in order to ensure quality control. Think of the model of health and safety licencing and inspection for restaurants and you’ve got the basic idea.
These four recommendations are illustrated in the diagram below.
4. Criticisms and Reflections
Citron and Pasquale go on to provide a detailed example of how a licencing and auditing system might work in the area of credit-scoring algorithms. I won’t go into those details here as the example is very US-centric (focusing on particular regulatory authorities in the US and their current powers and resources). Instead, I want to offer some general reflections and mild criticisms of their proposals.
In general, I favour their policy recommendations. I agree that there are significant problems associated with the black box society (as well as potential benefits) and we should work hard to minimise these problems. The procedural safeguards and regulatory frameworks proposed by the authors could very well assist in doing this. Though, as the authors themselves note, the window of opportunity for reforming this area may not open any time soon. Still, it is important to have policy proposals ready-to-go when it does.
Furthermore, I agree with the authors when they reject certain criticisms of transparency and openness. A standard objection is that transparency will allow people to “game the system”, i.e. generate good ratings when they actually present a risk. This may happen, but its importance is limited by two factors. First, if it does happen, it may just indicate that the scoring system is flawed and needs to be improved: reliable and accurate systems are generally more difficult to game. Transparency may facilitate the necessary improvements in the scoring system by allowing competitors to innovate and learn from past mistakes. Second, the costs associated with people “gaming the system” need to be considered in light of the costs of the present system. The current system did little to prevent the financial crisis in 2008, and its secrecy has an impact on procedural fairness and individual lives. Is the “gaming” worry sufficient to outweigh those costs?
Nevertheless, I have two concerns about the authors’ proposal. One is simply that it may be too idealistic. We are already drowning in information and besieged by intrusions into our personal data. Adding a series of procedural safeguards and rights to review data-gathering systems might do little to prevent the slide toward the algocratic society. People may not exercise their rights or may not care about the (possibly deleterious) ways in which their personal data are being used. In addition to this, and perhaps more subtly, I worry that proposals of this sort do little to empower the individuals affected by algocratic systems. Instead, they seem to empower epistemic elites and technocrats who have the time and ability to understand how these systems work. They will then be tasked with helping the rest of us to understand what is going on, advising us as to how these systems may be negatively impacting on us, and policing their implementation. In other words, proposals of this sort seem to just replace one set of problems — associated with a novel technological process — with an older and more familiar set of problems — associated with powerful human elites. But maybe the devil you know is better than the devil you don’t.
I’m not sure. Anyway, that brings us to the end of this discussion. Just to reiterate, there is plenty that I agree with in Citron and Pasquale’s paper. I am just keen to consider the broader implications.
No comments:
Post a Comment